This set of scripts tries to get statistics from the drupal projects commit history. It also tries to get as much as possible attribution from commit messages.
Overview
The following diagram provides an overview of the flow these scripts follow to create the results.
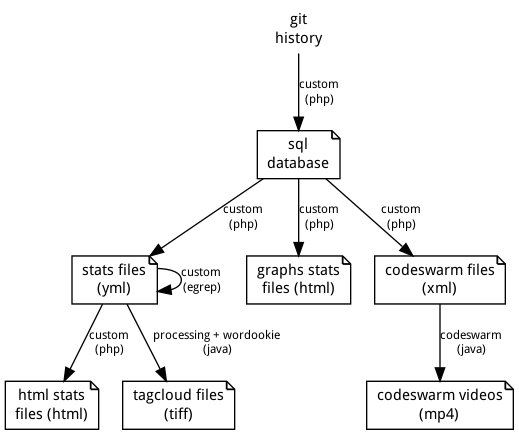
About output
By default one scenario is analyzed: the full history of the project. New scenarios can be added per git branch modifying the related config/analyzer.yml
If global maintainers key is in config/analyzer.yml an extra sub-scenario is added excluding them, so it is easier to identify people without push access.
The obtained information (database) is presented in the following three ways: plain statistics, html statistics, tagcloud images and codeswarm videos.
Database files
Database files are sqlite3 databases containing only one table contributions with the following fields:
-
id: incremental identifier, the primary key.
-
commit_hash: git commit hash(%H).
-
author_timestamp: git commit author timestamp(%at).
-
filename: Modified filename.
-
contributor: drupal.org username of contributor if mapped, more information below.
This table contains raw data extracted from the git history for easier access. It is used later to generate more relevant information, like codeswarm input files or the statistic files.
The database files are named with the pattern <project>-<scenario>.sqlite3. For example: vote_up_down-7.x-1.x.sqlite3 contains the raw data extracted from the the 7.x-1.x branch of Vote Up/Down project, and vote_up_down-full.sqlite3 contains that information corresponding with the whole repository history.
1,b8a1eab1fb8abb1238f1e5a63757f0d93b2a3cc6,1202326708,"INSTALL.txt","Dries"
This can be interpreted as Dries participated on the git commit b8a1eab and one of the affected files by that commit was INSTALL.txt
Plain statistics
Statistics files, stored at data/stats, contains the results of the analysis of one of the scenarios and one indicator, separated by a colon. There are two indicators: number of commits and number of file changes.
The statistics files are named with the pattern <project>-<scenario>-dev-participation-by-<indicator><|-no-maintainers>.txt. The -no-maintainers flag is added when maintainer are excluded of the file. E.g.: vote_up_down-7.x-1.x-dev-participation-by-commits.txt.

|
no-maintainers stats
Files ending with no-maintainers are the same files as files without this appended to the end except that core maintainers (e.g. in core Dries, webchick, catch, etc.) are removed from the file to avoid skew the results. Because core maintainers are the gatekeepers of the core repository and perform each commit they would receive a lot more participation than normal contributor mentioned on the commit messages. This is specially usefully for visualization generation of tagclougs, since sizes are relative to the maximum number in the set. |
Damien Tournoud:414
Assuming the following line comes from the file drupal-7.x-dev-participation-by-commits-no-maintainers.txt, this can be interpreted as Damien Tournoud contributed to 414 commits during the development of Drupal 7.x. If the contributor committed a modification to multiple files as part of a single commit it will count as a single contribution.
Damien Tournoud:1437
Assuming the following line comes from the file drupal-7.x-dev-participation-by-file-changes.txt, this can be interpreted as Damien Tournoud contributed to 1437 files changes during the development of Drupal 7.x. If the contributor committed a modification to multiple files as part of a single commit each file will be counted as a contribution. This will also result in a higher number of contributions counted as compared to by commit.
HTML statistics
A simple html page showing the results of each plain statistic in descending order.
Tagcloud images
Tagcloud files, stored at data/tagclouds are generated using Wordookie, an extension to the processing.org library that allows the generation of tagcloud images.
The generated images are tif files based on each of the plain statistics files generated before.
For reference, the source file for the generation is at wordookie/TagCloud/TagCloud.pde sketch file.
Graph HTML statistics
HTML containing graphs plotting information from database, they are self-describing.
Codeswarm videos
Codeswarm videos, stored at data/codeswarm, are generated with the xml file codeswarm program expects, which is based on the created sqlite database.
Threre are two types of videos: AVI and FLV files.
Requirements
This project uses several software pieces in order to produce its output.
-
php-git (libgit2 bindings for php)
-
curl (to autoretrieve some dependencies).
-
processing and wordookie (to generate tag clouds)
-
asciidoc, graphviz and source-highlight (to generate the compiled documentation)
Debian dependencies example
An example of dependencies installation on an Debian system, based on wheezy.
# Packaged software: git, make, php, unzip, php5-sqlite, asciidoc, graphviz, # curl apt-get install git php5-cli make unzip php5-sqlite curl asciidoc graphviz # UnPackaged software. # libgit2 requirements apt-get install zlib1g libssl1.0.0 # libgit2 build requirements apt-get install cmake build-essential libssl-dev php5-dev # libgit2 binding git clone git://github.com/libgit2/php-git # Follow instructions at https://github.com/libgit2/php-git#how-to-build to # build the library and the binding. # Uninstall build dependencies. apt-get purge cmake build-essential libssl-dev php5-dev # tagclouds: processing # Get the latest stable tarball for your architecture from # https://processing.org/download/?processing and extract it, e.g.: tar xf processing-2.2.1-linux64.tgz # tagclouds: wordookie # Create the containing directory. mkdir -p ~/sketchbook/libraries # Get tarball from # https://wordookie.googlecode.com/files/Wordookie-processing-r4.zip and # extract it there unzip Wordookie-processing-r4.zip # If you happen to run into 'java.lang.OutOfMemoryError: Java heap space' # increase the limit of memory used by java, modifying bin/TagCloud/Tagcloud # script addin parameter -Xmx512m (up to 512MB of heap memory) # X is required to generate tagclouds. On a desktop you probably already have # it, so let's focus on the headless case, let's use a vnc server. apt-get install --no-install-recommends tightvncserver xfonts-base # then start it vncserver # Set display on analyzer.yml if using vnc. This assumes the user running # vncserver is the same that the one running the analyzer scripts. e.g. # display: ':1' # codeswarm dependencies apt-get install --no-install-recommends ant openjdk-6-jdk libav-tools
Running
This project contains several scripts which could be run independently, but the usual case is about running one project from start to finish point.
Following a couple of examples on how to run analyzer for views and for drupal core on a 64-bit machine.
Manual run
If you are not running this periodically and you want to analyze a project not in projects directory, this is probably what you want to do.
# The root makefile only does preparation: build tagcloud app, generate # documentation and download some required software. make dist-init # Configure the project to use PROJECT=views cp -r projects/template_project/ projects/$PROJECT cd projects/$PROJECT git clone --mirror git://git.drupal.org/project/$PROJECT.git mirror # Modify config files: # Change at least project name and absolute path to git mirror. vi config/analyzer.yml # mail map: so git mails can be converted into d.o usernames. vi config/mail-map.yml # commits override: so e.g. typos can be fixed. vi config/commit_messages_override.yml # Create makefile for this project. ./init.sh # Make dbs, see data/dbs. make dbs # Make stats, see data/stats. make stats # Make graph stats, see data/graphstats. make graphstats # Make tag clouds images, see data/tagclouds. make tagclouds # Make codeswarm videos, see data/codeswarm. make codeswarm
This example used views project, and leaves all configuration by default. You probably want to change some of the configuration files to actually pass relevant information to scripts, e.g. which branches to analyze.
Automated run
There is a helper script in the runner git branch which helps the in process with an example script setting up environment variables for it as example in example.run.sh file.
This script does a couple of things: * Maintains a git mirror repository of a drupal.org project repository. * Reuses downloaded software instead of keep downloading it each run. On the case of from-scratch run, since in the same tree it will reuse downloaded tarballs if possible.
# Setup workdookie mkdir -p ~/sketchbook/libraries cd ~/sketchbook/libraries wget https://wordookie.googlecode.com/files/Wordookie-processing-r4.zip unzip Wordookie-processing-r4.zip # Download software manually to avoid re-download on each full run. mkdir extras cd extras wget https://getcomposer.org/composer.phar wget http://download.processing.org/processing-2.2.1-linux64.tgz tar xf processing-2.2.1-linux64.tgz wget https://codeswarm.googlecode.com/files/codeswarm-0.1.tar.gz curl https://codeload.github.com/flot/flot/zip/master > flot.zip curl https://codeload.github.com/markrcote/flot-axislabels/zip/master \ > flot-axislabels.zip wget https://github.com/twbs/bootstrap/releases/download/v3.0.3/bootstrap-3.0.3-dist.zip cd .. # Get runner branch git clone --branch='runner' \ git://git.drupal.org/sandbox/marvil07/1086028.git analyzer-runner cd analyzer-runner # Prepare the script. cp example.run.sh run.sh chmod u+x run.sh # Edit the script adding paths to downloaded software. vi run.sh # Finally run it. ./run.sh
Getting involved
If you have suggestions/fixes and want to contribute to make these scripts better please use the issue queue.